Guía de Desarrollo de Software
Guía de Desarrollo de Software para del desarrollo de aplicaciones sobre el repositorio de la Dirección de Información y Tecnologías DSIT de la Universidad de Los Andes. Versión 1.2.0

Desarrollo ETL
BUENAS PRACTICAS EN LA INTEGRACION DE DATOS
Actualmente existen múltiples herramientas de integración de datos con una gran versatilidad que nos facilita la construcción de una ETL robusta y funcional. Pero estas herramientas no resolverán todo por si solas, es necesario seguir unos pasos sencillos pero muy importantes para que nuestros desarrollos de integración sean útiles, óptimos y con un buen rendimiento de ejecución.
Extracción de los datos
A la hora de hacer la extracción de los datos se debe tener en cuenta que no somos los únicos usando esa fuente de información, por este motivo se debe valorar la necesidad y si es posible realizar la tarea de forma escalonada en bloques de menor tamaño filtrando por fechas más adecuadas para lograr el mínimo impacto. Otra buena practica a la hora de extraer los datos, si se trata de una tabla en una base de datos, es consultar solo la información requerida para el proceso.
Tipo de datos
Si la fuente de datos son datos no estructurados provenientes de una API, TOKENS, LINK o archivos en un SFTP, se debe tener una zona stage donde se descargarán los datos en una ubicación local para luego proceder con las transformaciones sin tener que volver a acceder a la fuente.
Procesos Escalables
La ETL debe ser construida de manera escalable y flexible, todas las extracciones en un paso, luego las transformaciones y por último todos los cargues hacia el destino, no se deben mezclar estos pasos.
Notificación de errores
Es muy importante desarrollar bloques de notificación de fallos vía correo, los pasos más cruciales del proceso deben contar con la opción de envío de notificación por falla.
Parámetros
En lo posible parametrizar todas las variables fijas dentro de la ETL, ya que con el tiempo las rutas, conexiones, librerías, nombres de tablas y archivos pueden cambiar, de esta manera se realizara más rápido el ajuste en un futuro.
Puntos de control
Incorporar en la ETL puntos de control que permitan ejecutar solo los bloques deseados, ejemplo ejecutar la ETL completa o solo la transformación y la carga o la extracción y la transformación.
Inserción de los datos
En lo posible, siempre que se inserten datos en una tabla de base de datos en el destino, usar un componente que permita hacer un merge en vez de un insert ya que si por alguna razón la ETL se volviera a ejecutar, la información podría duplicarse o podría fallar el paso por violación de constraint.
Uso de Properties
Para facilitar el uso de conexiones a servidores entre ambientes de dllo/qa/prod para bases de datos/sftp y otros se debe ejecutar una transformacion que permite leer un archivo .properties que debe estar por defecto en la ruta:
/home/pentaho/{nombre_proyecto}/{proyecto}.properties
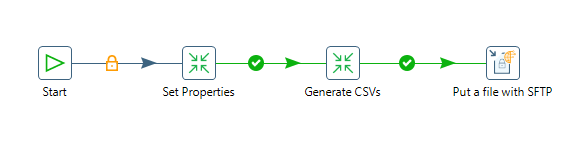
Conexiones BD:
Los properties son cargados como variable en pentaho y se puede hacer uso de ellas en cualquier job o transformacion del proyecto para este caso una base de datos:
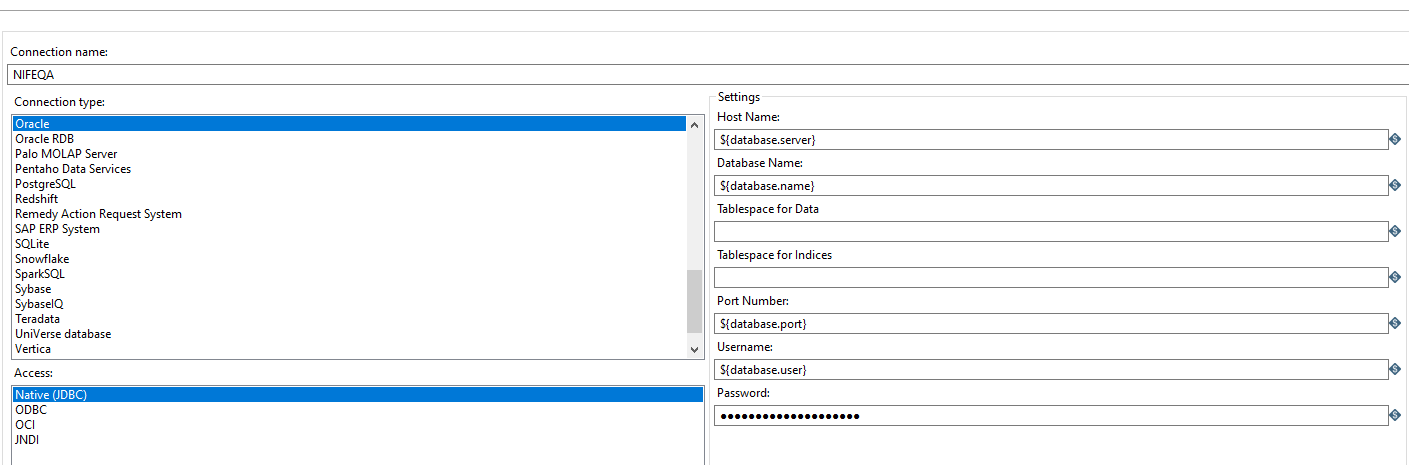
Uso de variables en la conexion:
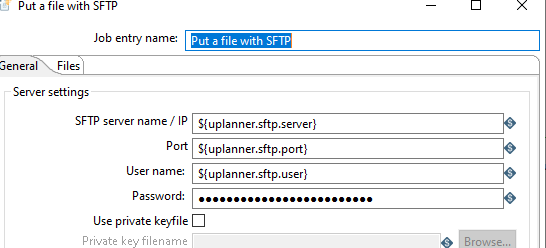
Conexiones SFTP:
Uso de properties en una conexion SFTP